
一、大体流程
1. 训练逻辑
mmdetection的训练逻辑是借助了mmcv中的Runner类,做了一层封装。按照正常的逻辑思考,如果我们要训练一个网络,至少要知道输入数据、模型、优化器、loss等信息,这些信息在tools/train.py以及mmdet/apis/train.py中都有对应的体现,例如在runner构建时传入的model、batch_processor以及optimizer,就分别对应了模型、loss、以及优化器,而runner.run调用时传入的data_loaders则对应了输入数据的部分。
值得注意的是batch_processor,它所做的其实就是通过喂入数据进行前馈计算得到loss,然后返回一个对应的记录了各种loss信息以及数据信息的字典,而这个返回的loss信息的处理则调用了parse_losses函数。这个函数所做的其实就是将一个字典中所有的loss字段分别记录,最后相加得到最终的loss。知道了这个过程,就可以知道,在计算loss的时候就已经要乘上每一项对应的系数,返回的时候也要返回一个对应不同类loss名称的字典。
2. 技术细节
此部分可以参照mmdetection的technical details中的内容。在mmdetection中,构成model的有四类组件
backbone:一般用于feature map的提取,例如resnet,vgg。
neck:在feature map和head之间的网络,例如FPN。
head:用于具体任务的网络,例如bbox regression、mask prediction。
roi extractor:从feature map进一步提取特征的部分,例如RoI Align。
而把这些部分组合起来的就是detector,mmdetection中有两个典型的detector,一个是SingleStageDetector,一个是TwoStageDetector。一般一个detector中要实现四个抽象方法
extract_feat():给出一个batch的图片,tensor的shape是(n, c, h, w),提取出feature map。forward_train():前馈计算得到loss。simple_test():单个scale图片的测试模式。aug_test():带有数据增强的测试模式。
下面将围绕retinanet涉及到的组件进行讲解。
二、网络结构
1. backbone
retinanet用到的backbone有res50,res101两种,当然还有ResNeXt等较新的网络。以res50为例,其有关backbone配置的部分如下
|
|
其中depth,num_stages都是resnet中常见的配置,out_indices也是指输出的特征图,与stage对应,此处代表C2,C3,C4,C5。而C2,C3,C4,C5分别对应resnet中第conv2_x、conv3_x、conv4_x、conv5_x块的输出,见下图
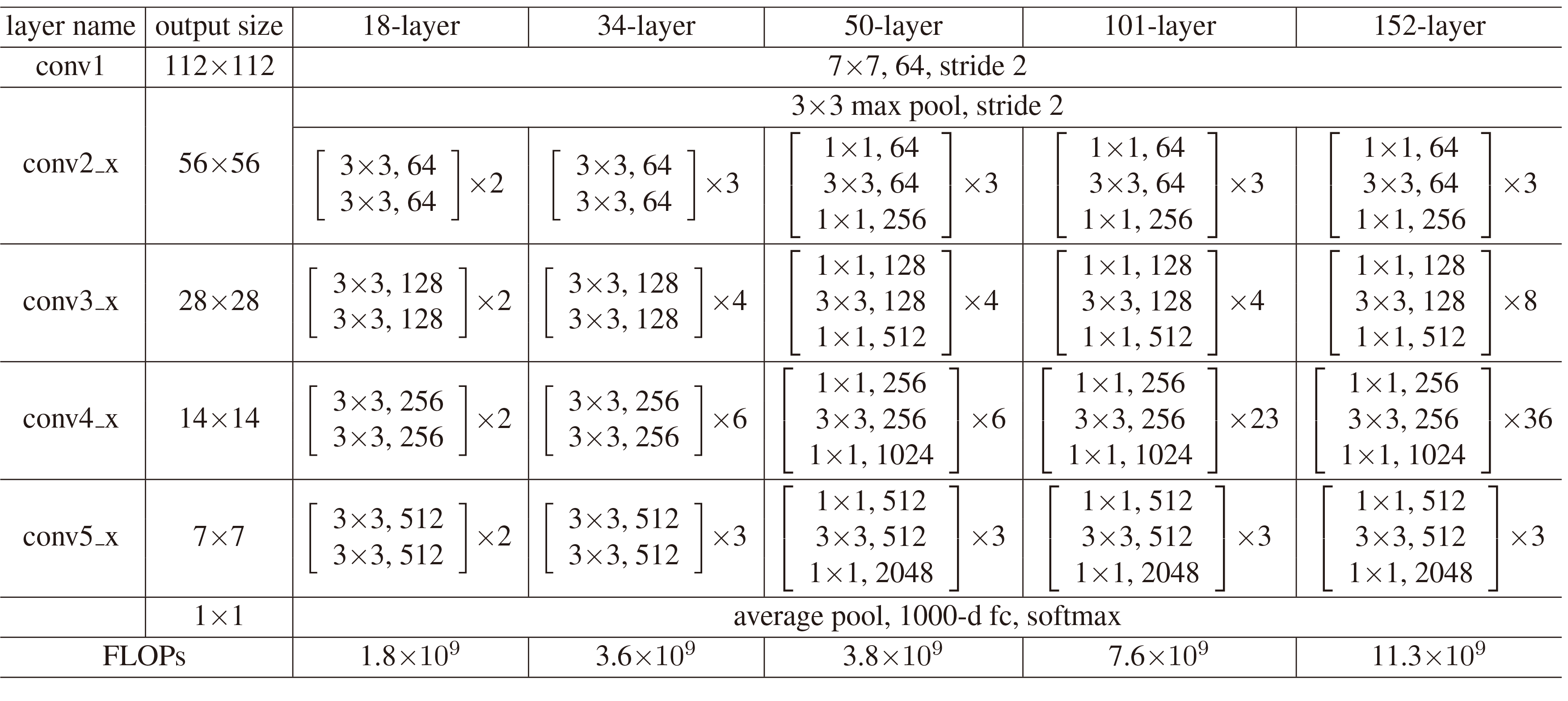
有一些关于resnet的细节。conv3_x、conv4_x、conv5_x的第一个block中会有一个stride为2的卷积用于减小特征图大小,在caffe的实现中,是在第一个1$\times$1的卷积处,而pytorch的实现中是在中间3$\times$3的卷积处,在mmdetection的代码中都有对应体现。另一个就是frozen_stages=1,由于要对resnet做finetune,所以要冻结一部分浅层的参数,此处默认冻结conv1,而fronzen_stages就是控制frozen_stages之前所有stage的卷积块都会被冻结,在这里也就是冻结第一个stage,conv2_x。除此之外还有一点就是冻结了网络中所有的BN层,因为batch数目太小了,加BN没有意义。
从代码可以看出,需要保存的特征图放在了一个list中。在retinanet里,backbone的输出就是四个特征图,[C2, C3, C4, C5]。
2. neck
neck部分使用的是FPN。configs中相关配置如下
|
|
- in_channels:输入特征图的channel数。
- out_channels:输出特征图的channel数。
- start_level:起始特征图的层数,例如start_level=1,意思就是不会使用C2,lateral connection只需要连接C3、C4、C5。
- add_extra_convs:添加额外卷积层,在retinanet中是用于生成P6和P7的conv。
- num_outs:输出特征图个数,在retinanet中是P3、P4、P5、P6、P7。
整体bottom-up以及top-down过程如下图所示
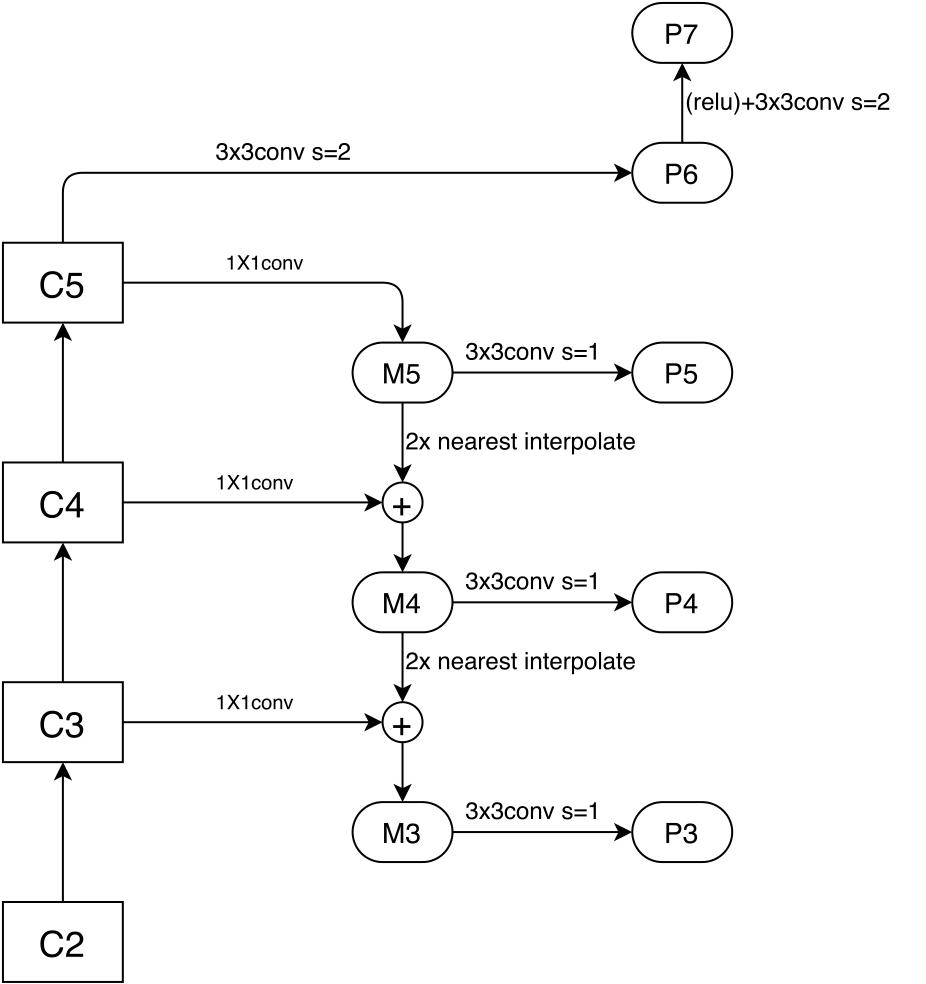
在经过neck后,会有五个尺度的特征图,同样保存在了一个list中,输出是[P3, P4, P5, P6, P6]。
3. head
(1)retinanet的head部分概述
在看这一部分之前,需要先了解一个重要的函数,这个函数屡次被用到,那就是mmdet/core/utils/misc.py中的multi_apply()函数,代码如下。
|
|
这个函数的作用其实就是将多个序列中的每一组元素都通过func函数,再将所得结果转置后返回。这样解释可能比较抽象,举一个例子:假如有两个列表list1,list2,我们要计算这两个列表的element-wise sum和element-wise product,我们可以通过一个函数同时返回两个数的和和差,如lambda x, y: (x + y, x * y)。再使用map函数,也就是:map(lambda x, y:(x + y, x * y), list1, list2),但是这样的结果是按照[(sum, product), (sum, product), ...]这样的形式组织的,所以要将它们转置,这样才能让结果中的和在一个列表中,差在一个列表中。
而用到这个函数则涉及到一个设计思想,那就是将问题按照不同的角度去分解。无论是在mmdet/models/anchor_heads/anchor_head.py还是在mmdetection/mmdet/core/anchor/anchor_target中,都能看到很多_single()结尾的函数,这样的函数解决的就是分解后的一个小问题。而将一个列表中每一个元素经过multi_apply()函数,再将结果组合起来,就得到了一个大问题的结果。具体到retinanet中,主要分解的角度有两个,一个是图片,另一个是特征图的尺度。这个角度的意思其实就是说在流程进行中,涉及到的数据的第一个维度的含义,第一种是图片数目,也就是一个batch中图片的数目作为第一个维度;第二种是特征图尺度的数目,在retinanet中有五个特征图,也就是第一个维度等于5。
需要逐图片解决的就是每个图片有关anchor的计算,比如anchor的assign,训练样本的sample,和label的获得等。而这一步解决后返回的结果需要是按特征图大小作为第一维度的,因为在mmdet/models/retina_head.py中的RetinaHead类完成了类别得分cls_scores,以及回归预测结果bbox_preds的计算,使用了forward_single()函数,这个函数是在RetinaHead的父类AnchorHead中被调用的,它的forward()只有一句话,那就是return multi_apply(self.forward_single, feats),也就是说得到的cls_scores的shape是[feat_size_num, batch_size, cls_num*A, N, M],bbox_preds的shape是[feat_size_num, batch_size, 4*A, N, M](A是同一个中心不同大小不同长宽比的anchor数)。这两部分都不是严格的Tensor,因为不同feat_size下的N和M不同,因此需要将feat_size_num个Tensor放在一个list中。所以在计算的时候,要逐个feat_size进行计算,也就是loss_single()所完成的计算。
RetinaHead同样涉及到配置字典,下面是具体参数
|
|
- num_classes:类别数,此处是默认算上背景的类别数,如果使用sigmoid分类,那样one hot向量全为0就可以代表背景类,就会将num_classes-1,具体代码可以参照
mmdet/models/anchor_heads/anchor_head.py中AnchorHead类的__init__()方法,第65到68行。 - in_channels:输入的特征图的channel数
- stacked_convs:在分类分支和回归分支中堆叠起来的conv层数。
- feat_channels:在堆叠起来的conv层中,特征的channel数
- octave_base_scale:用于计算anchor_scales的参数,具体在下面解释
- scales_per_octave:同上
- anchor_ratios:anchor的aspect ratio
- anchor_strides:在另一篇博文中有解释,可参照这篇博文
- target_means,target_stds:在rpn中有用到,用于测试阶段proposals的获得。retinanet不涉及。
(2)cls_scores以及bbox_preds的计算
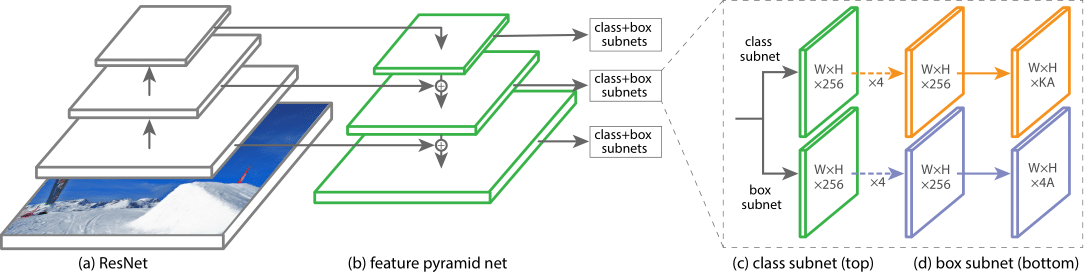
这一部分可以参照网络图来看RetinaHead中的代码
|
|
|
|
定义了几个堆叠层,与上面网络结构的描述基本一致。实现了forward_single(),这里注意到分类分支和回归分支是共享特征图的。forward_single()是用于处理一个尺度的特征图的,所以这个函数将会在multi_apply()中被使用,生成不同尺度特征图的分类和回归结果。因此输出的cls_scores,bbox_preds也是一个列表,cls_scores的存储格式是[shape([batch_size, cls_num*A, H1, W1]), shape([batch_size, cls_num*A, H2, W2]), ...],bbox_preds的存储格式是[shape([batch_size, 4*A, H1, W1]), shape([batch_size, 4*A, H2, W2]), ...]。
(3)anchor的获得
anchor的获得同样可以参照这篇博文,这里再结合代码细致说明一下anchor的生成过程。base_anchor的生成在那篇博文中解释的很详尽,需要解释的是滑动生成所有anchor的部分,这一部分的代码如下。
|
|
shift_x以及shift_y就是坐标偏移的大小,很好理解,那么如何通过这个生成x方向的偏移和y方向的偏移呢,这就用到了_meshgrid()这个函数。这个函数如下所示
|
|
这个函数看似复杂,其实结果很有规律,就是生成x方向所有的偏移和y方向上所有的偏移,之前的shift_x和shift_y仅仅是一组偏移。可以想象一个网格中,顶层有一行数字是x的偏移,那么要生成所有行x的偏移就要将x的偏移重复y的长度次;有一列数字是y的偏移,要生成所有列y的偏移就要讲y的偏移重复x的长度次,再将结果flat后输出,就得到了所有的偏移量,也就是shift_xx以及shift_yy。
之后将shift_xx, shift_yy叠起来,其实就生成了shift_x和shift_y的笛卡儿积,其形状是[2, H*W],因为base_anchor左上角和右下角的坐标是同步平移的,所以最终将两组shift_xx, shift_yy堆叠起来得到了形状是[4, H*W]的shifts。之后利用了广播机制,每个点有A个anchor,A个anchor中每个anchor的偏移量都是相同的,所以将对应需要广播的维度设为1,最终得到H*W*A个anchor的坐标。
这里面还有一个valid_flags的获得,代码如下
|
|
首先计算出合法的h和w的边界,然后将x方向上合法的中心部分设为1,y方向上合法的中心部分设为1,再利用_meshgrid得到两个方向上所有的合法情况,与操作得到两个方向都合法的点,由于每个点有A个框,一个框合法余下的暂时都算作合法,expand每个点的结果,最终flat得到一个shape([H*W*A])的Tensor,记录着每个框的合法情况。
不同尺度的anchor及其valid_flag的获取是在mmdet/models/anchor_heads/anchor_head.py中AnchorHead类的方法get_anchors()中得到。最终会得到一个list[list[Tensors]],最外层是图片个数,再内一层是尺度个数,里面的Tensors的shape是[H*W*4, 4],其中H和W代表对应尺度特征图的高和宽。
(4)Anchor target的获取
① anchor_target (mmdet/core/anchor/anchor_target.py)
得到了anchor后要通过两步来得到训练的目标。
- Assign:把各个anchors分配给gt box的过程
- Sample:从所有的bbox中sample出训练样本的过程。
1个batch中每张图片的训练目标的获取都是调用mmdet/core/anchor/anchor_target.py中anchor_target()函数得到的。下面来大致看一下这个函数干了什么,再细致看Assign和Sample的过程。
首先获取了每张图片中,每种尺度anchor的数目
|
|
然后将每张图片中所有尺度的anchor放在一起,例如:有两个尺度,第一个尺度有20个anchor,其对应Tensor的形状是[20, 4],第二个尺度有10个anchor,对应Tensor的形状是[10, 4],那么会将该图片中所有尺度的anchor放在一起,变成一个[30, 4]的anchor。
得到了每张图的所有anchor,就逐个图片调用anchor_target_single()函数,计算得到每张图片的每个anchor的label及其对应的weights(后面会解释),到对应gt box的delta值及其weights,以及正样本和负样本的下标。注意此时结果是一个list[Tensor],第一维度是图片。
|
|
接下来计算所有图片中所有正样本以及负样本的个数
|
|
最后将所有以图片为第一维度的结果,通过函数images_to_levels(),转换成以特征图尺度个数为第一维度的结果,供loss计算使用。具体做法如下
|
|
下面是image_to_levels()的实现,首先将列表中每个img的结果堆叠起来,最后再将结果按每个尺度中anchor个数切片即可。此处以bbox_targets为例,假如一个batch_size有2张图片,一共有三个尺度的特征图分别有30、20、10个anchor。 那么一开始的输入就是[shape([60, 4]), shape([60, 4])],将其堆叠起来就能得到shape([2, 60, 4])的Tensor,之后再按照特征图个数切片,最后得到[shape([2, 30, 4]), shape([2, 20, 4]), shape([2, 10, 4])]的list。
② anchor_target_single (mmdet/core/anchor/anchor_target.py)
在这里只需要关注一张图中所有的anchor即可,首先用anchors = flat_anchors[inside_flags, :]来将所有有效的anchor提取出来,以减少计算量。而为了与cls_scores和bbox_preds的形状相符合,最后所有结果还要unmap回函数输入flat_anchors中。
再然后使用Assigner和Sampler来获取训练样本,这里内容较多,决定单开贴另说。只提一个小细节,由于使用了focal loss,一定程度解决了前景背景类别不均衡问题,所以sample的时候sample了全部的背景样本。对于其他的detector则需要采取一定措施限制负样本的个数,保持正负样本比例。
经过这两个部分后,就得到了一个SamplingResult ,这个类定义在了mmdet/core/bbox/samplers/sampling_result.py,里面主要保存了如下内容
- pos_inds:正样本的下标
- neg_inds:负样本的下标
- pos_bboxes:正样本的bbox坐标
- neg_bboxes:负样本的bbox坐标
- pos_is_gt:正样本的bbox是否就是gt_bbox
- num_gts:gt_bbox的个数
- pos_assigned_gt_inds:正样本所对应的gt bbox在gt_bboxes中的下标
- pos_gt_bboxes:每个正样本对应的gt_bbox的坐标
- pos_gt_labels:每个正样本对应的gt的label
之后通过这些信息来计算target和weight,代码如下
|
|
注意到这里面的bbox_targets和label结果中都对应了weights且shape与它们自己相同,这些weights默认都是0。对于bbox_targets_weights,需要将正样本weight设为1,而对于label,需要将正负样本的weight都设为1。注意到这里面不一定正负样本加起来就是全部valid anchor,因为assign过程中有一部分anchor会根据IoU大小被忽略,所以正负样本都要特地赋值为1。
最后就是将结果对应回flat_anchors,调用了同一文件中的unmap()函数。这个unmap的过程很简单,代码如下
|
|
这是unmap函数
|
|
这里要注意一个细节,label_channels > 1的情况下就要调用expand_binary_label()函数。label_channels的值其实是在mmdet/models/anchor_heads/anchor_head.py中计算的,代码如下
|
|
含义就是如果使用sigmoid得到分类结果(每个channel都是一个二分类,属于该类目标值为1,不属于该类目标值为0),那么label_channels就是分类结果的channel数;否则为1。retinanet要使用focal loss,自然每个channel都是一个二分类,所以这里label_channels肯定大于1。这样expand_binary_label()的作用就清楚了,之前每个anchor的label都是对应label的序号,现在要将这个序号转化为一个one-hot的vector(背景类为全0的vector),以下是expand_binary_label()的实现,其实就是一个将序号转化为one-hot vector的过程,并不复杂。
|
|
(5) loss的计算
loss的计算就是逐个尺度进行计算的过程,调用了multi_apply()函数将每个尺度下的预测和标签信息等传入loss_single()进行计算。如下
|
|
这些传入的变量都是在之前的步骤中得到的,不难知道他们代表的含义。除了num_total_samples需要解释一下,表面看这个变量的含义是sample出的总样本的个数,但是它的计算方式却是num_total_samples = (num_total_pos if self.use_focal_loss else num_total_pos + num_total_neg)。为什么在使用focal loss的时候仅仅取正样本呢,这是因为这个变量在loss的计算中作为avg_factor使用,类似于loss的平均值,其它的检测方式中都有对负样本的sample过程,这样正负样本的和就不会很多。但是在focal loss中使用的是PseudoSampler,近乎于取了全部的负样本,这样正负样本的和就会非常大,loss的和除完这个数会非常小,使得训练无法进行。这个细节在focal loss的paper中有提到,如下
The total focal loss of an image is computed as the sum of the focal loss over all ~100k anchors, normalized by the number of anchors assigned to a ground-truth box.
下面就具体看一下一个尺度的loss的计算,这些是在mmdet/models/anchor_heads/anchor_head.py中的loss_single()函数中计算的。下面逐个部分看一下loss的计算。
① 分类损失
首先是cls_loss的计算,先将labels以及label_weights reshape成[N, cls_num]的形式(在focal loss中使用二分类损失,如果不用二分类损失每个anchor的label就是一个数字,就直接reshape成一个[N]的Tensor即可);对于cls_score来说,它的shape是[batch_size, num_cls, H, W],所以需要先交换维度后再reshape成[N, cls_num]的Tensor。接下来就是cls_criterion的选择,这部分不用解释,根据具体设置选择即可,在retinanet中选择的是weighted_sigmoid_focal_loss。
|
|
下面看一下focal loss的具体实现,其中涉及到mmdet/core/loss/losses.py中的sigmoid_focal_loss()和weighted_sigmoid_focal_loss()。主要计算其实在sigmoid_focal_loss()中。在看代码之前首先看一下focal loss的定义
其中$\alpha$和$\gamma$都属于超参,而$p_t$代表属于第t类的概率,而对于retinanet输出的每个channel在经过sigmoid后都代表属于该类别的概率,所以对于二分类的$p_t$和$\alpha_t$可以写作如下形式,设网络某个channel的输出为$p$,该类的label记作$t\in \{0,1\}$。
代入focal loss的计算式,可以得到
下面就可以利用这个计算式来计算focal loss,除去系数,其实剩下部分就是一个BCELoss,所以只有系数需要自己计算,而且不要忘记用系数与weight做element-wise product,将无效的anchor的loss置为0。代码如下
|
|
② 回归损失
下面是边框回归loss的计算,类似地,先对bbox_targets、bbox_weights和bbox_pred进行了reshape。随后调用weighted_smoothl1()进行计算。
|
|
同样地,weighted_smoothl1()定义在mmdet/core/loss/losses.py中,这里面beta代表回归损失的系数,其余就是损失的计算。注意,在计算完loss后,同样要与weight做element-wise product,将非正样本的无用的loss清0。这里说一点题外话,这种给loss上加weight的做法非常像掩码,在mmdetection中weight都设置成与对应的Tensor相同的shape,例如bbox_target的shape是[N, 4],weight的shape也是[N, 4],并没有直接设置为[N],这样十分清晰,要忽略不相关训练样本的loss直接做element-wise product就好。weighted_smoothl1()代码如下:
|
|